실제로 예측을 하고자 할 떄 보통 하나 이상의 변수들을 고려해야 합니다. multiple linear regression은 다양한 입력 변수들을 사용하는 예측모델입니다.

위 이미지를 예로 설명하면,
집가격(y)를 예측한다고 할 때, x1(침실수), x2=층 수, x3=지어진연수, x4=크기 4가지 feature(n=4)가 있습니다 .
feature= dimension=attribute
x(2)는 =[3 2 40 127](열벡터로)가 되고, x3(2)는 30 입니다
default는 한상 열벡터이고, row vector 즉 [3 2 40 127]로 표현하고 싶다하면, transpose를 사용하여 표현합니다.
예측 모델 식은 다음과 같습니다.

세타0,1,2,3은 각 변수의 가중치이고, x1,2,3는 각 feature입니다.
각 feature의 값 크기가 제각각입니다. 예를들어 집 크기는1-2000까지 이고, 침실 수는 1-5범위입니다.
이러한 차이는 스케일러(min-max 등)를 통해 0~1사이의 값으로 스케일링하여 계산합니다.
경사하강법(gradient descent)으로 미분 값(기울기)이 최소가 되는 점을 찾아 알맞은 weight(가중치 매개변수)를 찾습니다. 즉, 경사하강법은 해당 함수의 최소값 위치를 찾기 위해 Cost Function의 경사 반대 방향으로 정의한 step size를 가지고 조금씩 움직여 가면서 최적의 파라미터를 찾으려는 방법으로, 파라미터(편미분한 벡터)를 조금씩 움직여가며 계산합니다.
예제를 통해 살펴보겠습니다.
자동차의 여러 기술적인 사양들을 고려하여 연비를 예측하는 auto miles per gallon(MPG) dataset을 예시 데이터 셋으로 사용하겠습니다.
1.1 Dataset
1. 데이터 불러오기
import pandas
import seaborn
seaborn.set()
from urllib.request import urlretrieve
URL = 'https://go.gwu.edu/engcomp6data3'
urlretrieve(URL, 'auto_mpg.csv')
mpg_data = pandas.read_csv('/content/auto_mpg.csv')
mpg_data.head()
mpg_data.info()를 통해서 Data에 대한 정보를 살펴보겠습니다

총 392개의 데이터가 있고 9개의 정보들이 있습니다.
여기서 car name 은 object로 자동차의 이름을 담고 있습니다.
그리고 origin은 int로 정수 형태이지만 이것이 만들어진 도시로 categorical 한 값입니다(ex. 서울 : 1, 경기 : 2, ... ).
그렇기 때문에 이번에 linear regression을 할 때는 car name, origin 값은 제외하고 생각하도록 하겠습니다.
y_col = 'mpg'
x_cols = mpg_data.columns.drop(['car name', 'origin', 'mpg']) # also drop mpg column
print(x_cols)1.2 Data exploration
먼저 linear regression을 진행하기 전에 자동차의 정보들과 연비와의 1대1 상관관계를 알아보겠습니다.
시각화해서 보는 것이 가장 직관적으로 이해하기 쉽습니다.
seaborn.pairplot(data=mpg_data, height=5, aspect=1,
x_vars=x_cols,
y_vars=y_col);
Accerlation과 model_year 의 정보는 양의 상관관계에 있고 나머지는 음의 상관관계에 있습니다.
이러한 상관관계를 통해서 linear model 이 연비를 예측하는데 충분하다는 것을 알 수 있습니다.
1.3 Linear model in matrix form

from autograd import numpy
from autograd import grad
X = mpg_data[x_cols].values
X = numpy.hstack((numpy.ones((X.shape[0], 1)), X)) # pad 1s to the left of input matrix
y = mpg_data[y_col].values
print("X.shape = {}, y.shape = {}".format(X.shape, y.shape))
#X.shape = (392, 7), y.shape = (392,)mean squared error로 cost function을 정의하겠습니다.
def linear_regression(params, X):
'''
The linear regression model in matrix form.
Arguments:
params: 1D array of weights for the linear model
X : 2D array of input values
Returns:
1D array of predicted values
'''
return numpy.dot(X, params)
def cost_function(params, model, X, y):
'''
The mean squared error loss function.
Arguments:
params: 1D array of weights for the linear model
model : function for the linear regression model
X : 2D array of input values
y : 1D array of predicted values
Returns:
float, mean squared error
'''
y_pred = model(params, X)
return numpy.mean( numpy.sum((y-y_pred)**2) )1.4 Find the weights using gradient descent
이제 Gradient descent로 cost function을 최소로 해주는 계수를 찾아보겠습니다. autograd.grad()함수로 기울기를 구해서 사용하겠습니다.
gradient = grad(cost_function)기울기값이 잘 구해지는지 랜덤한 값을 통해 알아보겠습니다.
gradient(numpy.random.rand(X.shape[1]), linear_regression, X, y)
1.5 Feature scaling
Gradient descent를 진행했더니 loss가 무한대로 발산했습니다. 이것은 입력 변수들 중에 특정 값들이 너무 커서 일어난 일입니다. 입력 데이터들의 max 와 min 값을 한번 출력해보면,

from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
X_scaled = min_max_scaler.fit_transform(mpg_data[x_cols])
X_scaled = numpy.hstack((numpy.ones((X_scaled.shape[0], 1)), X_scaled))
pandas.DataFrame(X_scaled).describe().loc[['max', 'min']]
0번째 행은 처음에 1을 추가해준 행이므로 1로 유지되는게 맞습니다. 이제 변화된 데이터로 다시 gradient descent를 진행해 보겠습니다.
max_iter = 1000
alpha = 0.001
params = numpy.zeros(X.shape[1])
for i in range(max_iter):
descent = gradient(params, linear_regression, X_scaled, y)
params = params - descent * alpha
loss = cost_function(params, linear_regression, X_scaled, y)
if i%100 == 0:
print("iteration {}, loss = {}".format(i, loss))

1.6 How accurate is the model?
이제 우리가 만든 모델이 얼마나 정확한지 알아보도록 하겠습니다. Regression 문제에서는 주로 두개의 기본 지표가 있습니다. Mean absolute error(MAE)와 root mean squared error(RMSE)입니다. 두개의 식은 다음과 같습니다.
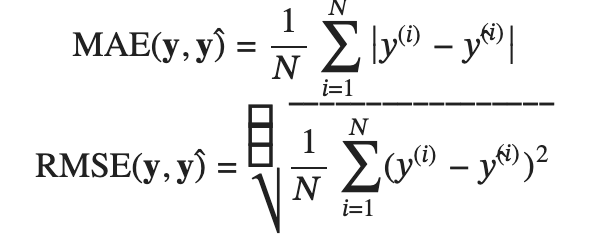
from sklearn.metrics import mean_absolute_error, mean_squared_error
mae = mean_absolute_error(y, y_pred_gd)
rmse = mean_squared_error(y, y_pred_gd, squared=False)
print("mae = {}".format(mae))
print("rmse = {}".format(rmse))mae = 2.613991601156043
rmse = 3.40552056741184
'머신러닝' 카테고리의 다른 글
| 다중 로지스틱 회귀 (소프트맥스 회귀) (0) | 2022.12.05 |
|---|---|
| 로지스틱 회귀 sklearn logistic regression iris python (0) | 2022.12.04 |
| [머신러닝4] Logistic Regression 로지스틱 회귀 pyhton (0) | 2022.11.30 |
| [머신러닝2] Polynomial Regression python (0) | 2022.11.30 |
| [머신러닝1] 선형회귀 Linear Regression , gradient descent pyhton (0) | 2022.11.28 |