next.js 에서 https 로 실행하는 법 "scripts": { "dev": "next dev --experimental-https"}package.json 에 dev부분 수정 후 npm run dev 로 다시 실행하면 http가 아닌 https localhost 환경에서 실행됨 안된다면 , 다음과같이 설치 후 실행npm i next@latest react@latest react-dom@latest eslint-config-next@latest 진짜 너무 편하다 카테고리 없음 2024.05.03
react에서 props란? Props는 React에서 컴포넌트 간에 데이터를 전달하는 방법입니다. Props는 "properties"의 줄임말로, 부모 컴포넌트로부터 자식 컴포넌트로 데이터를 전달할 때 사용됩니다. Props는 읽기 전용이며, 컴포넌트 내부에서는 변경할 수 없습니다. 이는 컴포넌트가 순수 함수처럼 동작하도록 하여, 예측 가능한 동작을 보장합니다.Props 사용 방법Props를 사용하는 기본적인 방법은 다음과 같습니다:Props 전달하기: 부모 컴포넌트에서 자식 컴포넌트로 props를 전달할 때는, 자식 컴포넌트 태그의 속성으로 추가합니다.jsx// 부모 컴포넌트function ParentComponent() { return ;}Props 사용하기: 자식 컴포넌트에서는 함수의 매개변수로 props를 받아 사용할 수.. 카테고리 없음 2024.04.25
타입스크리트에서 인터페이스란? (개념, 사용법) 타입스크립트(Typescript)에서 인터페이스(interface)는 객체의 타입을 정의하는 방법 중 하나입니다. 인터페이스를 사용하면 객체가 특정 구조를 가지고 있음을 명시할 수 있으며, 이를 통해 코드의 안정성을 높이고 에러를 줄일 수 있습니다. 인터페이스는 클래스, 함수, 배열 등 다양한 곳에서 사용할 수 있으며, 코드의 가독성과 재사용성을 높이는 데 도움이 됩니다.인터페이스 정의 방법인터페이스는 interface 키워드를 사용하여 정의합니다. 그리고 그 안에 해당 객체가 가져야 할 속성과 그 타입을 명시합니다.typescriptinterface Person { name: string; age: number;}위 예시에서 Person 인터페이스는 name과 age 두 가지 속성을 가지고 있으며,.. 카테고리 없음 2024.04.25
[자바스크립트] 웹팩이란? 웹팩(Webpack)은 자바스크립트(JS) 애플리케이션을 위한 정적 모듈 번들러입니다. 웹 애플리케이션을 구성하는 자원(HTML, CSS, 이미지, JS 파일 등)을 모두 모듈로 보고, 이러한 모듈들을 의존성 그래프로 만들어 하나 또는 여러 개의 번들로 결합하는 도구입니다. 웹팩을 사용함으로써 개발자는 애플리케이션을 모듈 방식으로 구성할 수 있고, 최종적으로 브라우저에서 사용할 수 있는 형태로 자원들을 번들링할 수 있습니다. 웹팩의 주요 기능은 다음과 같습니다: 로더(Loaders): 웹팩은 오직 자바스크립트와 JSON 파일만 이해할 수 있습니다. 로더를 사용하면 웹팩이 다른 타입의 파일들을 처리하여 모듈로 변환할 수 있게 합니다. 예를 들어, CSS, 이미지, HTML 파일들을 자바스크립트 모듈로 변환.. 카테고리 없음 2024.04.22
fastAPI pydamic으로 스키마 설정하기 schema.py 에 Pydantic 모델을 사용하여 요청 및 응답 스키마를 정의 예시: from pydantic import BaseModel from typing import Optional class JapaneseBase(BaseModel): type: Optional[str] = None letter: str pronounciation: str audio: Optional[str] = None lesson: Optional[int] = None img: Optional[str] = None # 선택적 필드 vid: Optional[str] = None # 선택적 필드 class JapaneseCreate(JapaneseBase): pass 다시 routers/ 폴더의 해당 파일로가서, 라우터에 .. 대회 프로젝트/데이터셋 모음 2024.04.19
FastAPI 에서 의존성 주입 이란? (Dependency Injection) FastAPI의 "Dependency Injection"은 FastAPI 프레임워크에서 제공하는 핵심 기능 중 하나입니다. Dependency Injection은 의존성 주입이라고도 하며, 이는 코드의 결합도를 낮추고, 유지보수와 테스트가 용이하도록 도와주는 설계 패턴입니다. FastAPI에서는 이를 통해 더욱 깔끔하고 효율적으로 API를 개발할 수 있습니다.(재사용성, 효율성 증가의 효과) Dependency Injection의 기본 원리 FastAPI에서 Dependency Injection을 사용하면, 함수나 클래스의 인스턴스를 직접 생성하지 않고, FastAPI가 실행 시간(runtime)에 의존성을 주입해줍니다. 이로써, 필요한 객체나 설정, 데이터베이스 연결 등을 효율적으로 관리하고 재사용할 .. 카테고리 없음 2024.04.19
fastapi로 라우터 작성 어떻게 할까 예제에서 본 방식(alemdic 사용) https://github.com/tiangolo/full-stack-fastapi-template/tree/master/backend/app router = APIRouter( prefix="/", ) @router.get("/list")# /list 경로로 GET 요청이 들어오면 question_list 함수가 호출됩니다. def question_list(): db = SessionLocal() _question_list = db.query(Question).order_by(Question.create_date.desc()).all() db.close() return _question_list 단점 : 실제 애플리케이션에서는 데이터베이스 세션을 관리하는 방법에 .. 카테고리 없음 2024.04.18
fastapi 에서 alembic 사용하기 SQLAlchemy + pydamic 보다는 SQLAlchemy+ alembic를 사용하는 것이 추세. 데이터베이스 구조 변경이 더 쉽기 때문입니다. Alembic을 사용하여 데이터베이스 마이그레이션을 수행하는 과정은 기본적으로 몇 단계로 나뉩니다. 여기에는 초기 설정, 마이그레이션 스크립트의 생성, 그리고 마이그레이션의 적용이 포함됩니다. SQLAlchemy 모델을 기반으로 한 마이그레이션을 만들기 위해, 먼저 Alembic 설정을 완료해야 합니다. 그 후, 모델에 대한 변경 사항을 반영하는 마이그레이션 스크립트를 생성하고 적용해야 합니다. Alembic 설정: 프로젝트 루트에서 $ pip install alembic ; alembic init alembic 명령어를 실행하여 Alembic을 초기화합니.. 카테고리 없음 2024.04.18
fastAPI 로 백엔드 시작하기 (환경 세팅, 폴더 구조, mysql 사용) flask를 써봤다면 조금 익숙할 수도 있다. 예시 참고 https://github.com/tiangolo/full-stack-fastapi-template GitHub - tiangolo/full-stack-fastapi-template: Full stack, modern web application template. Using FastAPI, React, SQLModel, Post Full stack, modern web application template. Using FastAPI, React, SQLModel, PostgreSQL, Docker, GitHub Actions, automatic HTTPS and more. - tiangolo/full-stack-fastapi-template git.. 카테고리 없음 2024.04.18
mysql 에서 username 생성하고 권한주기 테스트를하려면 루트보다는 유저를 생성해서 하는 것이 좋다. mysql에서 user를 생성하는 가장 기본적인 방법은 아래를 수행하는 것이다. CREATE USER 'username'@'host' IDENTIFIED BY 'password'; 여기서 Your password does not satisfy the current policy requirements. 라는 에러가 날 수 있다. 이는 비밀번호 때문인데 SHOW VARIABLES LIKE 'validate_password%'; +--------------------------------------+-------+ | Variable_name | Value | +--------------------------------------+-------+ | .. 카테고리 없음 2024.04.17
TypeORM을 사용한 데이터베이스 마이그레이션이란 기본적인 정보 얻기 https://typeorm.io/ TypeORM - Amazing ORM for TypeScript and JavaScript (ES7, ES6, ES5). Supports MySQL, PostgreSQL, MariaDB, SQLite, MS SQL Server, typeorm.io TypeORM을 사용한 데이터베이스 마이그레이션은 TypeORM이 제공하는 기능을 활용하여 데이터베이스의 스키마를 버전 관리하는 프로세스입니다. 이는 애플리케이션의 데이터 모델이 변경될 때마다 데이터베이스 스키마를 안전하게 변경할 수 있도록 도와줍니다. 마이그레이션을 사용하면 데이터베이스 스키마 변경 사항을 코드 형태로 관리할 수 있으며, 이러한 변경 사항을 버전별로 추적할 수 있습니다. TypeORM .. 카테고리 없음 2024.04.17
<1> 간단한 웹사이트 만들기 nextjs, react https://ui.shadcn.com/에서 설치 https://ui.shadcn.com/docs/installation/next Next.js Install and configure Next.js. ui.shadcn.com vscode extension 설치 - 간단한 명령어로 코드 작성 가능 (auth)폴더에 sign-in . sign-up폴더 추가 (root) meeting [id] - dynamic routes (참고: https://nextjs.org/docs/pages/building-your-application/routing/dynamic-routes) (home) page.tsx, layout.tsx extension설치 1. ES7+ React/Redux/React-Native snip.. 카테고리 없음 2024.04.05
자바스크립트 타입스크립트 차이, 타입스크립트 기초 타입스크립트 : 타입을 명세한다. 타입오류를 쉽게 찾을 수 있고 유효성 검증에 용이 1. 자바스크립트 function greet(name) { return "Hello, " + name + "!"; } console.log(greet("John")); 2. 타입스크립트 - 파라미터, 리턴값의 타입을 명세 function greet(name: string): string { return "Hello, " + name + "!"; } console.log(greet("John")); [타입스크립트 기초 문법] 변수 선언: 변수를 선언할 때는 let 또는 const 키워드를 사용합니다 let num: number = 10; const message: string = "Hello,World!"; 함수 선언: 함.. 카테고리 없음 2024.04.05
react, next.js14 배우기 위한 로드맵 React 기본 문법 컴포넌트 (Component) JSX, TSX 상태 (State) 속성 (Props) 이벤트 처리 async, await 조건부 렌더링 리스트와 키 React 고급 문법 컴포넌트 생명주기 (Lifecycle) Hook 사용하기 (useState, useEffect 등) Context API Refs Next.js 기본 폴더 구조 익히기 라우팅 데이터 가져오기(Data fetching),(getStaticProps, getServerSideProps 등) 동적 라우팅과 쿼리 파라미터 API Routes 생성하기 이미지 최적화 CSS tailwind css 카테고리 없음 2024.04.04
flask requests.post 에서 보낸 데이터 다 받지 못하는 경우 python requests.post 에서 보낸 데이터를 . 다받지 못하는 문제 발생 해결: json.dumps로 씌우고 headers를 명시해주어야 한다. 얘가 어떤 데이터인지 알려주어야 복잡한 구조도 잘 받음 headers = {'Content-Type': 'application/json', 'Accept':'application/json'} requests.post(client_url, data=json.dumps(result), headers=headers) Python 2024.03.19
json.load()와 json.loads()의 차이 json.load()와 json.loads()의 차이는, load는 json을 파일을 읽고 loads는 json 형태의 문자열을 읽어 파이썬 객체로 반환함 만약 문자열(json 형태)을 json.load()에 파싱하면, 다음과 같은 오류가 뜸 data = json.load(user_bucklist) AttributeError: 'str' object has no attribute 'read' Python 2024.03.14
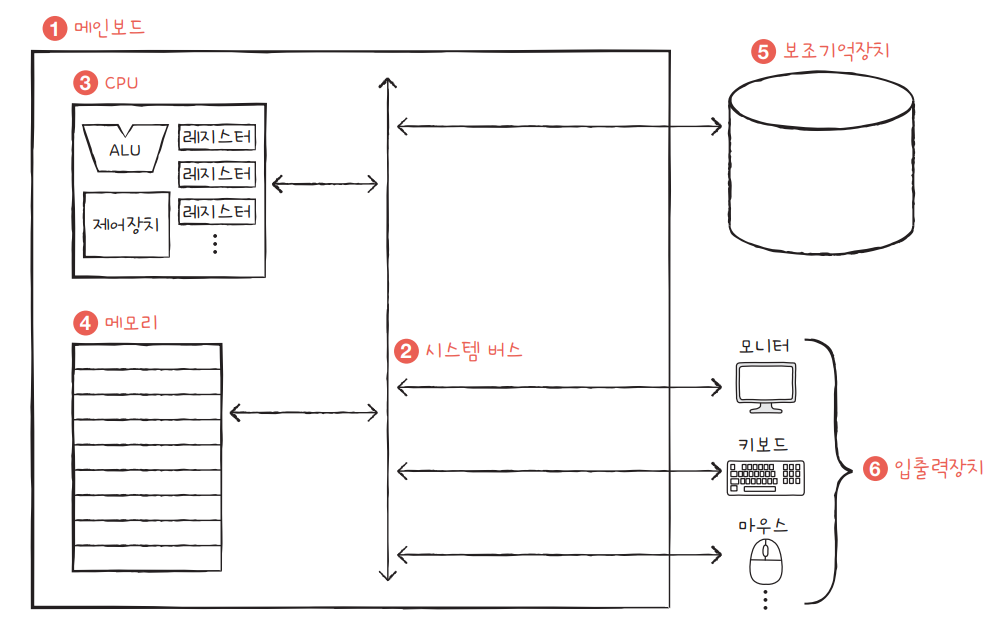
컴퓨터구조 0. CPU, 메모리, 보조기억장치, 입출력장치 간단한 개요 메인보드라고 하는 판떼기에 모든것을 놓고 서로 동작할 수 있도록 함. 이들은 버스라는 통로를 통해 서로 주고받을 수 있다. 메모리에는 현재 실행하는 프로그램의 명령어와 데이터가 저장되어있고, 현재 실행안되는 것은 보조기억장치에 저장 메모리에는 명령어,데이터는 주소로 저장됨 cpu는 산술논리장치(계산기), 제어장치 , 레지스터로 이루어져 있다.] 레지스터엔 임시로 값이 저장되고 제어장치는 메모리 읽기, 메모리 쓰기와같은 제어 신호르르 보낸다. cpu는 발열이 심하기 때문에 팬이 달려있다. 보조기억장치로 전원이 꺼져도 컴퓨터는 기억할 수 있음. 하드 디스크, SSD, USB 메모리, DVD, CD-ROM, 외장하드 보조기억장치/입출력장치는 개념상 구분하지 않아도 된다. 라즈베리 파이 컴퓨터에서 .. 기본지식/컴퓨터 구조 2024.03.01
git, github 원격에서 코드 업데이트 하는법 github에서 계정 토큰 발행 $ git init $ git remote add origin [원격저장소 주소] - [원격저장소 주소] 는 code에서 나오는 https://~~~git //브랜치 이름 바꾸기 $ git branch -m master main //파일 업로드 - add → commit → push 순서 //원격 저장소의 파일 가져오기 $ git pull (또는 git pull origin [브랜치 이름]) main //모든 변경사항을 올리는 경우 $ git add . //특정한 파일만 올리는 경우 $ git add [파일/디렉토리] $ git commit -m "commit message" $ git push (또는 git push origin [브랜치 이름]) //추가적인 명령어 //.. 기본지식/협업 2024.03.01
[코딩테스트] 문단에서 가장 흔한 단어 찾기 - re.sub, counter 객체 [문제] paragraph에서 대소문자, 쉼표 구두점등을 무시하고, banned 단어에 포함되지 않은 단어 중 가장 많이 등장한 단어 반환 Example 1: Input: paragraph = "Bob hit a ball, the hit BALL flew far after it was hit.", banned = ["hit"] Output: "ball" Explanation: "hit" occurs 3 times, but it is a banned word. "ball" occurs twice (and no other word does), so it is the most frequent non-banned word in the paragraph. Note that words in the paragraph.. Python/코딩테스트 2024.01.13
감정 분류 모델 만들고 성능 개선까지 (BERT, GPT2, RoBERTa, DistilBERT) 간단한 긍부정 이진 분류 모델을 만들었다. 전체코드는 깃헙에서 볼 수 있다! https://github.com/Juyoung-b/Improving-the-Performance-of-Sentiment-Classification GitHub - Juyoung-b/Improving-the-Performance-of-Sentiment-Classification Contribute to Juyoung-b/Improving-the-Performance-of-Sentiment-Classification development by creating an account on GitHub. github.com 영어로 된 레스토랑 리뷰를 가지고, 긍정(1), 부정(0)으로 분류하는 간단한 task 모델이다. 이번 프로젝트에선.. 대회 프로젝트/프로젝트 2023.01.29