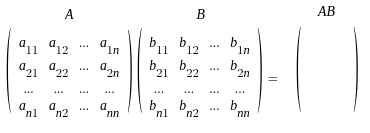
github에서 계정 토큰 발행 $ git init $ git remote add origin [원격저장소 주소] - [원격저장소 주소] 는 code에서 나오는 https://~~~git //브랜치 이름 바꾸기 $ git branch -m master main //파일 업로드 - add → commit → push 순서 //원격 저장소의 파일 가져오기 $ git pull (또는 git pull origin [브랜치 이름]) main //모든 변경사항을 올리는 경우 $ git add . //특정한 파일만 올리는 경우 $ git add [파일/디렉토리] $ git commit -m "commit message" $ git push (또는 git push origin [브랜치 이름]) //추가적인 명령어 //..